An unfortunate side effect: How privacy trends are weakening website security

There is strong industry agreement that the recent wave of increased consumer security and privacy protections is a terrific idea. Empowering folks to prevent intrusive tracking of their online activity is a positive development, and it’s proof that some of the largest companies are finally starting to respect end users’ data and digital experience.
However, one of the unintended consequences of these newfound protections is how the changes to common identification methods, such as cookie tracking and device fingerprinting, can skew the success rate of some of the most commonly accepted and adopted security software and tools - one being bot mitigation.
Enterprises and security vendors alike need to better understand how these privacy improvements affect the way companies ascertain which traffic is human and which is fake, and thus the impact it has on stopping online fraud.
The Problem of False Positives
A false positive, by definition, is when your security software incorrectly categorizes legitimate human traffic as malicious. When it comes to bot mitigation, the more aggressively rules are tuned, the more susceptible it becomes to false positives, because it needs to quickly decide whether to grant requests for indeterminate risk scores. As a result, real users are often unintentionally blocked from websites or need to be served a CAPTCHA for validation to be allowed entry.
No one wants to prevent legitimate users from accessing their business, but being too lax on protections allows in bad traffic, and being too strong creates a poor user experience and lowers online conversions. Too often, solutions err on the side of the latter.
Humans in Disguise
With the increase in privacy protections and customizable settings, everyday users have the power to mask who they are and what they do on the internet. These changes have been overwhelmingly popular with consumers and privacy advocates alike, but ironically, the move towards more privacy on the web can actually compromise overall website security.
This trend is unintentionally exacerbating false positives and rendering traditional rule-based and risk-score dependent solutions inadequate for detecting malicious, automated requests.
Device Fingerprinting
In order to understand why this is such an issue, you have to first know how the majority of bot detection solutions work. They rely heavily on device fingerprinting to analyze device attributes and malicious behavior. Device fingerprinting is performed client-side and collects information such as IP addresses, user agent header, advanced device attributes (e.g. hardware imperfections) and cookie identifiers.
Over the years, the information collected from the device fingerprint has become a major element of the information analytics engines use to decide whether traffic is bot or human. Device fingerprints, in theory, are supposed to be like real fingerprints, in that each is unique and can easily identify one user from another.
Fingerprinting technology has evolved by collecting the increasing abundance of information client-side. But what happens when device fingerprints presented by humans start to look like those presented by bad bots?
Unfortunately, this is what’s happening as a result of online privacy trends. The evidence of a legitimate user gained through device fingerprinting methods is increasingly vanishing.
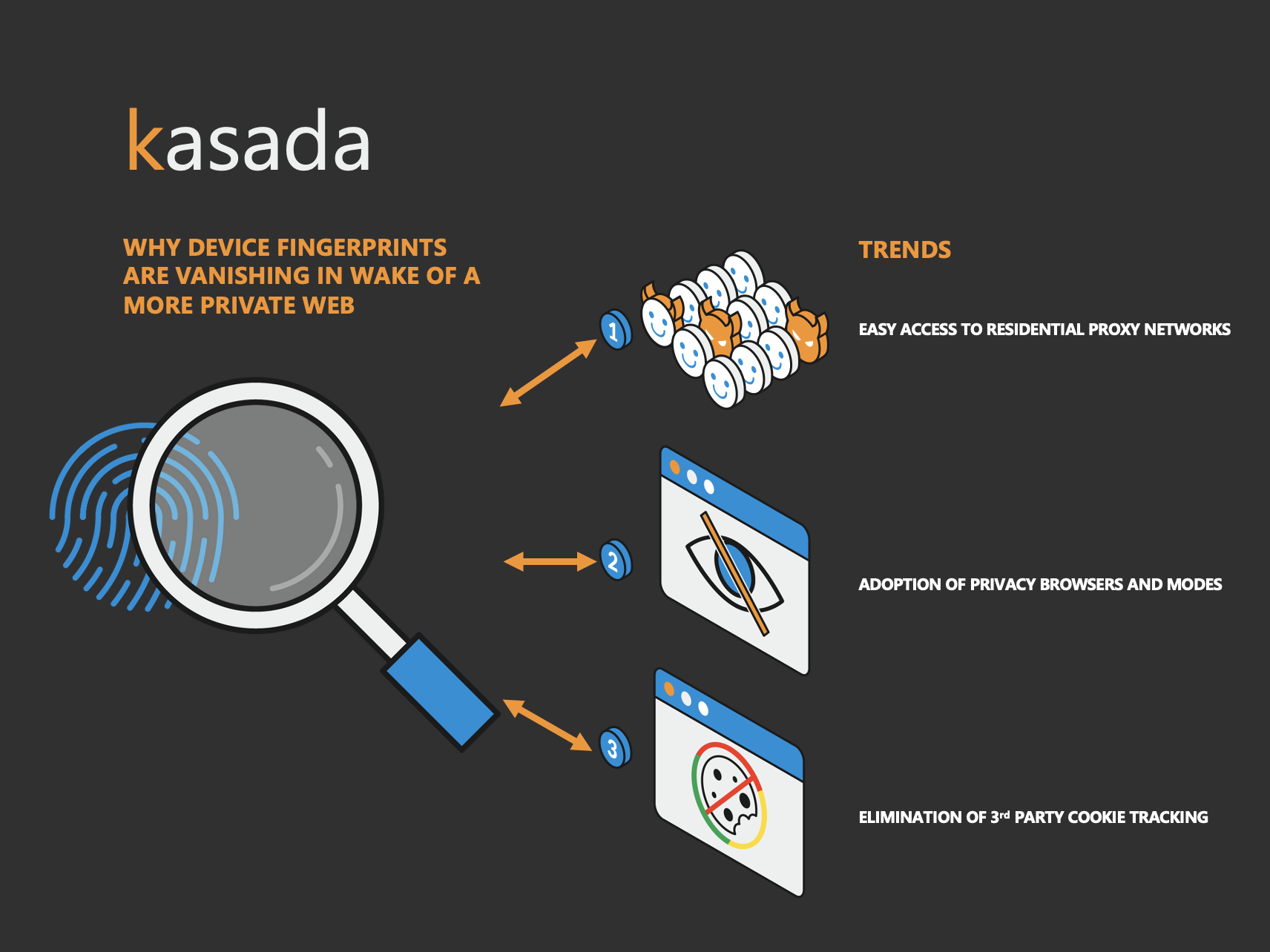
It’s much harder to be confident that device fingerprinting can still be an accurate tool to defend against bad bots. Here are several online privacy trends that are accelerating the digital fingerprint’s loss in effectiveness:
- Residential Proxy Networks
It’s well-known that bot operators leverage residential proxy networks to hide their fraudulent activities behind seemingly innocuous IP addresses. There’s also been an increase in legitimate users extending beyond traditional data-center proxies to hide behind the same sorts of residential proxy networks. Residential proxy networks have become increasingly inexpensive, and in some cases, free; they provide a seemingly endless combination of IP addresses and user agents to mask your activity.
While some of these users hide behind residential proxies for suspect reasons, such as to overcome access to restricted content (e.g. geographic restrictions), many use it to genuinely ensure their privacy online and protect personal data from being stolen.
Bot and human traffic look remarkably similar when hidden behind residential proxies. You can’t rely on IP addresses and user agents to distinguish between humans and bad bots when hidden behind them.
- Privacy Mode and Private Browsers
Private browsing modes, such as Chrome Incognito Mode and Edge InPrivate Browsing, reduce the density of information stored about you. These modes take moderate measures to protect your privacy. For example, when you use private browsing, your browser will no longer store your viewing history, cookies accepted, or forms completed. It’s estimated that more than 46% of Americans have used a private browsing mode within their browser of choice.
Furthermore, privacy browsers, along the lines of Brave, Tor, Yandex, Opera, and customized Firefox take privacy on the web to the next level. They add additional layers, such as blocking or randomizing device fingerprinting, offer tracking protection (coupled with privacy search engines such as DuckDuckGo to avoid tracking your search history), and delete cookies - making ad trackers ineffective.
These privacy browsers command about 10% of the total market today and are increasing in popularity. They have enough market share to present major challenges for anti-bot detection solutions reliant on device fingerprinting.
With market share continuing to expand, it’s becoming increasingly clear that advanced device identifiers and first-party cookies will also soon be ineffective at identifying the difference between bots and humans.
- 3rd-Party Cookie Tracking
There will always be a substantial percentage of Internet users who don’t use privacy modes or browsers; simply put, Google and Microsoft have too much market share. But even for these users, device fingerprinting will be increasingly difficult. One example is due to the widely publicized effort by Google to eliminate 3rd party cookie tracking. And while the timeframe has recently been delayed to 2023, this will inevitably make it more difficult to identify suspect behavior.
3rd party cookies collected from the device fingerprinting process are often used as a tell sign of bot-driven automation. For example, if a particular session with an identified set of 3rd party cookies has tried to do 100 logins, then it’s an indicator that you’ll want to force them to revalidate and establish a new session as it's unlikely to be a human.
3rd-party cookies are fast becoming another dead-end when it comes to distinguishing between humans and malicious automated traffic.
Where Do We Go From Here?
The way that traffic is examined to determine human or bot needs to adapt to the changing privacy preferences of everyday users. Digital fingerprints, cookies, or other legacy identification and measurement tools can no longer be relied upon.
This creates a real problem for companies that have based their processes upon these protections. If they’re blocking legitimate traffic on a regular basis, you face the real threat of pushing your customers to a competitor’s website. At the same time, you can’t take the opposite approach and simply loosen rules and restrictions to the point where you’ve made it easier for traffic to get in - and create security problems for your business.
Modern approaches to this problem need to evolve and look beyond attempts to update or tweak these legacy fingerprinting methods and flip the approach. Instead, look for the tell-tale, indisputable evidence of automation that presents itself whenever a bot interacts with websites, mobile apps or APIs. Every request should have to prove itself as legitimate, instead of the security solution looking to determine if it’s false. The idea of applying a zero-trust approach to bot mitigation takes on much more importance given the changes in user privacy preferences. Assume traffic is guilty and then let it then prove its innocence before allowing it into your system. No need for risk scores, rules or CAPTCHAs.
Embracing this philosophy will help you eliminate the false positives and negatives that are inevitably occurring due to the movement towards a more private web.
Looking for a reprint of this article?
From high-res PDFs to custom plaques, order your copy today!








