Making a Business Case for ‘Edge’ Network Intelligence
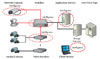
The intelligence can be located in different parts of a video surveillance system, creating a centralized or distributed architecture.

In a DVR-based installation, the IV functionality is located in the DVR along with all other functions such as digitization, compression, video management, and storage.
By intelligently designing an IV system and distributing the load, the overall costs of a system can be substantially lowered and the performance improved.
Centralized Systems
In centralized architectures, all the video from the cameras is brought back to the “head-end” for centralized processing. Legacy infrastructures with analog cameras mostly use traditional multi-function DVRs (digital video recorders) at the head-end, whereas in a network video system, PC servers are used for video processing.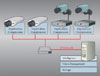
In a PC server–based installation, the IV functionality is located in the server along with all other functions such as video management and storage.
DVR-Based Installations
When using traditional security video systems, the surveillance video from analog cameras is fed into an IV-enabled DVR (Figure 2). DVRs have encoder cards that convert the video from analog to digital format and then perform the intelligent analysis (e.g., people counting or car license plate recognition). They also compress the video, record it and distribute resulting alarms and video output to authorized operators.In this architecture, each analog camera is connected by an individual coax cable to a DVR. DVRs are generally embedded devices. Some have proprietary video formats. Although this approach works adequately for small installations with a limited number of cameras, it is not scalable or flexible. Each DVR comes with a specific number of inputs, and adding even one additional camera entails the addition of another DVR, which is a costly proposition. In addition, because DVRs are proprietary embedded devices, they cannot be networked easily and do not support general network utilities such as firewalls and virus protection.
DVRs were traditionally designed to store and view a limited number of cameras and, as a result, they do not have much computational power. When DVRs run newer IV applications that require a lot of processing power, they can support only a fraction of the number of cameras they were designed to support.
PC Server–Based Installations
To overcome the limitations of DVRs, newer centralized architectures use commercial off-the-shelf (COTS) PC servers for video processing (Figure 3). The video from network cameras is brought directly to servers over a network. If the cameras are analog, the video is digitized first by video encoders and then transmitted over a network to a server.This architecture is more flexible and scalable than proprietary DVR-based architectures because digitization and compression have been pushed out to the network cameras and video encoders. However, because the servers perform many of the processor-intensive tasks (transcoding the video, managing the storage and processing the video for analysis), they need considerable processing power and each server is only able to process a relatively small number of cameras.
Distributed Systems
Distributed architectures are designed to overcome the limitations of a centralized system that overloads a central point such as a PC server or DVR. By distributing the processing to different elements in a network, bandwidth consumption can be reduced.Network-centric Installations
In typical network video systems, switches and routers are used to send video to appropriate components in a system. As a video stream passes through such gateways, the video data can be analyzed. The extracted metadata can then be streamed instead of the video. This eliminates the dependency on a central unit and the potential bandwidth concerns in centralized infrastructures. However, because the switches or routers need to have much more processing power, their costs are higher. In addition, the design of the network is much more complicated.Intelligence at the Edge Installations
The most scalable, cost-effective and flexible architecture is based on “intelligence at the edge,” which means processing the video as much as possible inside the network cameras or video encoders. (Analog cameras do not have the capability to analyze video.)Network cameras or video encoders with video motion detection, for example, can make use of this feature by sending video only when it detects motion in defined areas of a scene. Otherwise, no video is sent. The load on the infrastructure, including the required number of operators, falls dramatically. For specialized applications such as automatic number plate recognition or people counting, the impact of running applications in the camera is dramatic: The cameras can extract the required data (number plate information or number of people) and send only the data with perhaps a few snapshots.
This architecture uses the least amount of bandwidth because the cameras can send out metadata and intelligently figure out the required video to send. This significantly reduces the cost and complexity eliminates the drawbacks of a centralized architecture.
Another advantage of having video processing at the edge – or partly at the edge – is that it significantly reduces the cost of the servers needed in running IV applications. Servers that would typically process four to twelve video streams in a centralized IV solution would be able to handle more than 100 video streams if the intelligence processing were done in the network cameras. In some applications, where simply the data is needed and not the video – for example, people counting or automatic number plate recognition – the resulting data can be sent directly into a database, which further reduces the load on servers.
Processing video in intelligent edge devices also greatly enhances the quality of the analysis because the cameras can process raw video data before it is tainted by lossy compression formats such as MPEG-4. A lossy compression method is one where compressing data and then decompressing it retrieves data that may well be different from the original, but is close enough to be useful in some way.
Processing raw video is ideal for video-processing algorithms. In centralized architectures, compressed video is sent to the servers because streaming raw video would take up too much bandwidth. However, the servers would then have to decompress or transcode the compressed video packets to process them. This increases costs by increasing the number of servers required for a given number of cameras.
In summary, an IV architecture based on intelligent edge devices can result in significant cost savings and enhanced performance by:
- Reducing the costs of PC servers required to process the video. Because of the need for fewer servers, there also are lower power consumption and maintenance costs. In addition, in certain environments such as retail stores where there are generally no “server rooms,” installing a large number of servers is simply impractical.
- Reducing network bandwidth utilization and costs. Reducing the data rates by streaming only essential information means that lower-priced network components can be used.
About the Book
From CRC Press, Intelligent Network Video by Fredrick Nilsson provides detailed coverage of advanced digital networking and intelligent video capabilities and optimization. You can order by phone or online. In the US, Canada, Central & South America: Phone: 1(800)272-7737 or orders@crcpress.com.Links
Looking for a reprint of this article?
From high-res PDFs to custom plaques, order your copy today!







